The China Study II: Carbohydrates, fat, calories, insulin, and obesity
The “great blogosphere debate” rages on regarding the effects of carbohydrates and insulin on health. A lot of action has been happening recently on Peter’s blog, with knowledgeable folks chiming in, such as Peter himself, Dr. Harris, Dr. B.G. (my sista from anotha mista), John, Nigel, CarbSane, Gunther G., Ed, and many others.
I like to see open debate among people who hold different views consistently, are willing to back them up with at least some evidence, and keep on challenging each other’s views. It is very unlikely that any one person holds the whole truth regarding health matters. Unfortunately this type of debate also confuses a lot of people, particularly those blog lurkers who want to get all of their health information from one single source.
Part of that “great blogosphere debate” debate hinges on the effect of low or high carbohydrate dieting on total calorie consumption. Well, let us see what the China Study II data can tell us about that, and about a few other things.
WarpPLS was used to do the analyses below. For other China Study analyses, many using WarpPLS as well as HealthCorrelator for Excel, click here. For the dataset used here, visit the HealthCorrelator for Excel site and check under the sample datasets area.
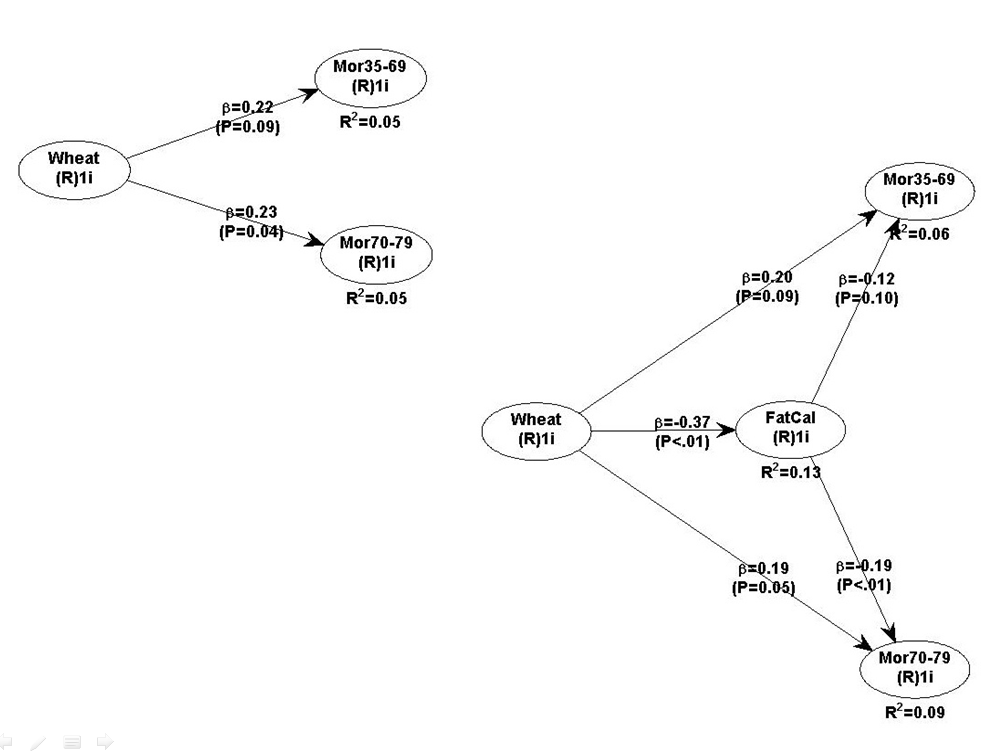
The two graphs below show the relationships between various foods, carbohydrates as a percentage of total calories, and total calorie consumption. A basic linear analysis was employed here. As carbohydrates as a percentage of total calories go up, the diet generally becomes a high carbohydrate diet. As it goes down, we see a move to the low carbohydrate end of the scale.

The left parts of the two graphs above are very similar. They tell us that wheat flour consumption is very strongly and negatively associated with rice consumption; i.e., wheat flour displaces rice. They tell us that fruit consumption is positively associated with rice consumption. They also tell us that high wheat flour consumption is strongly and positively associated with being on a high carbohydrate diet.
Neither rice nor fruit consumption has a statistically significant influence on whether the diet is high or low in carbohydrates, with rice having some effect and fruit practically none. But wheat flour consumption does. Increases in wheat flour consumption lead to a clear move toward the high carbohydrate diet end of the scale.
People may find the above results odd, but they should realize that white glutinous rice is only 20 percent carbohydrate, whereas wheat flour products are usually 50 percent carbohydrate or more. Someone consuming 400 g of white rice per day, and no other carbohydrates, will be consuming only 80 g of carbohydrates per day. Someone consuming 400 g of wheat flour products will be consuming 200 g of carbohydrates per day or more.
Fruits generally have much less carbohydrate than white rice, even very sweet fruits. For example, an apple is about 12 percent carbohydrate.
There is a measure that reflects the above differences somewhat. That measure is the glycemic load of a food; not to be confused with the glycemic index.
The right parts of the graphs above tell us something else. They tell us that the percentage of carbohydrates in one’s diet is strongly associated with total calorie consumption, and that this is not the case with percentage of fat in one’s diet.
Given the above, one may be interested in looking at the contribution of individual foods to total calorie consumption. The graph below focuses on that. The results take nonlinearity into consideration; they were generated using the Warp3 algorithm option of WarpPLS.

As you can see, wheat flour consumption is more strongly associated with total calories than rice; both associations being positive. Animal food consumption is negatively associated, somewhat weakly but statistically significantly, with total calories. Let me repeat for emphasis: negatively associated. This means that, as animal food consumption goes up, total calories consumed go down.
These results may seem paradoxical, but keep in mind that animal foods displace wheat flour in this dataset. Note that I am not saying that wheat flour consumption is a confounder; it is controlled for in the model above.
What does this all mean?
Increases in both wheat flour and rice consumption lead to increases in total caloric intake in this dataset. Wheat has a stronger effect. One plausible mechanism for this is abnormally high blood glucose elevations promoting abnormally high insulin responses. Refined carbohydrate-rich foods are particularly good at raising blood glucose fast and keeping it elevated, because they usually contain a lot of easily digestible carbohydrates. The amounts here are significantly higher than anything our body is “designed” to handle.
In normoglycemic folks, that could lead to a “lite” version of reactive hypoglycemia, leading to hunger again after a few hours following food consumption. Insulin drives calories, as fat, into adipocytes. It also keeps those calories there. If insulin is abnormally elevated for longer than it should be, one becomes hungry while storing fat; the fat that should have been released to meet the energy needs of the body. Over time, more calories are consumed; and they add up.
The above interpretation is consistent with the result that the percentage of fat in one’s diet has a statistically non-significant effect on total calorie consumption. That association, although non-significant, is negative. Again, this looks paradoxical, but in this sample animal fat displaces wheat flour.
Moreover, fat leads to no insulin response. If it comes from animals foods, fat is satiating not only because so much in our body is made of fat and/or requires fat to run properly; but also because animal fat contains micronutrients, and helps with the absorption of those micronutrients.
Fats from oils, even the healthy ones like coconut oil, just do not have the latter properties to the same extent as unprocessed fats from animal foods. Think slow-cooking meat with some water, making it release its fat, and then consuming all that fat as a sauce together with the meat.
In the absence of industrialized foods, typically we feel hungry for those foods that contain nutrients that our body needs at a particular point in time. This is a subconscious mechanism, which I believe relies in part on past experience; the reason why we have “acquired tastes”.
Incidentally, fructose leads to no insulin response either. Fructose is naturally found mostly in fruits, in relatively small amounts when compared with industrial foods rich in refined sugars.
And no, the pancreas does not get “tired” from secreting insulin.
The more refined a carbohydrate-rich food is, the more carbohydrates it tends to pack per unit of weight. Carbohydrates also contribute calories; about 4 calories per g. Thus more carbohydrates should translate into more calories.
If someone consumes 50 g of carbohydrates per day in excess of caloric needs, that will translate into about 22.2 g of body fat being stored. Over a month, that will be approximately 666.7 g. Over a year, that will be 8 kg, or 17.6 lbs. Over 5 years, that will be 40 kg, or 88 lbs. This is only from carbohydrates; it does not consider other macronutrients.
There is no need to resort to the “tired pancreas” theory of late-onset insulin resistance to explain obesity in this context. Insulin resistance is, more often than not, a direct result of obesity. Type 2 diabetes is by far the most common type of diabetes; and most type 2 diabetics become obese or overweight before they become diabetic. There is clearly a genetic effect here as well, which seems to moderate the relationship between body fat gain and liver as well as pancreas dysfunction.
It is not that hard to become obese consuming refined carbohydrate-rich foods. It seems to be much harder to become obese consuming animal foods, or fruits.
I like to see open debate among people who hold different views consistently, are willing to back them up with at least some evidence, and keep on challenging each other’s views. It is very unlikely that any one person holds the whole truth regarding health matters. Unfortunately this type of debate also confuses a lot of people, particularly those blog lurkers who want to get all of their health information from one single source.
Part of that “great blogosphere debate” debate hinges on the effect of low or high carbohydrate dieting on total calorie consumption. Well, let us see what the China Study II data can tell us about that, and about a few other things.
WarpPLS was used to do the analyses below. For other China Study analyses, many using WarpPLS as well as HealthCorrelator for Excel, click here. For the dataset used here, visit the HealthCorrelator for Excel site and check under the sample datasets area.
The two graphs below show the relationships between various foods, carbohydrates as a percentage of total calories, and total calorie consumption. A basic linear analysis was employed here. As carbohydrates as a percentage of total calories go up, the diet generally becomes a high carbohydrate diet. As it goes down, we see a move to the low carbohydrate end of the scale.

The left parts of the two graphs above are very similar. They tell us that wheat flour consumption is very strongly and negatively associated with rice consumption; i.e., wheat flour displaces rice. They tell us that fruit consumption is positively associated with rice consumption. They also tell us that high wheat flour consumption is strongly and positively associated with being on a high carbohydrate diet.
Neither rice nor fruit consumption has a statistically significant influence on whether the diet is high or low in carbohydrates, with rice having some effect and fruit practically none. But wheat flour consumption does. Increases in wheat flour consumption lead to a clear move toward the high carbohydrate diet end of the scale.
People may find the above results odd, but they should realize that white glutinous rice is only 20 percent carbohydrate, whereas wheat flour products are usually 50 percent carbohydrate or more. Someone consuming 400 g of white rice per day, and no other carbohydrates, will be consuming only 80 g of carbohydrates per day. Someone consuming 400 g of wheat flour products will be consuming 200 g of carbohydrates per day or more.
Fruits generally have much less carbohydrate than white rice, even very sweet fruits. For example, an apple is about 12 percent carbohydrate.
There is a measure that reflects the above differences somewhat. That measure is the glycemic load of a food; not to be confused with the glycemic index.
The right parts of the graphs above tell us something else. They tell us that the percentage of carbohydrates in one’s diet is strongly associated with total calorie consumption, and that this is not the case with percentage of fat in one’s diet.
Given the above, one may be interested in looking at the contribution of individual foods to total calorie consumption. The graph below focuses on that. The results take nonlinearity into consideration; they were generated using the Warp3 algorithm option of WarpPLS.

As you can see, wheat flour consumption is more strongly associated with total calories than rice; both associations being positive. Animal food consumption is negatively associated, somewhat weakly but statistically significantly, with total calories. Let me repeat for emphasis: negatively associated. This means that, as animal food consumption goes up, total calories consumed go down.
These results may seem paradoxical, but keep in mind that animal foods displace wheat flour in this dataset. Note that I am not saying that wheat flour consumption is a confounder; it is controlled for in the model above.
What does this all mean?
Increases in both wheat flour and rice consumption lead to increases in total caloric intake in this dataset. Wheat has a stronger effect. One plausible mechanism for this is abnormally high blood glucose elevations promoting abnormally high insulin responses. Refined carbohydrate-rich foods are particularly good at raising blood glucose fast and keeping it elevated, because they usually contain a lot of easily digestible carbohydrates. The amounts here are significantly higher than anything our body is “designed” to handle.
In normoglycemic folks, that could lead to a “lite” version of reactive hypoglycemia, leading to hunger again after a few hours following food consumption. Insulin drives calories, as fat, into adipocytes. It also keeps those calories there. If insulin is abnormally elevated for longer than it should be, one becomes hungry while storing fat; the fat that should have been released to meet the energy needs of the body. Over time, more calories are consumed; and they add up.
The above interpretation is consistent with the result that the percentage of fat in one’s diet has a statistically non-significant effect on total calorie consumption. That association, although non-significant, is negative. Again, this looks paradoxical, but in this sample animal fat displaces wheat flour.
Moreover, fat leads to no insulin response. If it comes from animals foods, fat is satiating not only because so much in our body is made of fat and/or requires fat to run properly; but also because animal fat contains micronutrients, and helps with the absorption of those micronutrients.
Fats from oils, even the healthy ones like coconut oil, just do not have the latter properties to the same extent as unprocessed fats from animal foods. Think slow-cooking meat with some water, making it release its fat, and then consuming all that fat as a sauce together with the meat.
In the absence of industrialized foods, typically we feel hungry for those foods that contain nutrients that our body needs at a particular point in time. This is a subconscious mechanism, which I believe relies in part on past experience; the reason why we have “acquired tastes”.
Incidentally, fructose leads to no insulin response either. Fructose is naturally found mostly in fruits, in relatively small amounts when compared with industrial foods rich in refined sugars.
And no, the pancreas does not get “tired” from secreting insulin.
The more refined a carbohydrate-rich food is, the more carbohydrates it tends to pack per unit of weight. Carbohydrates also contribute calories; about 4 calories per g. Thus more carbohydrates should translate into more calories.
If someone consumes 50 g of carbohydrates per day in excess of caloric needs, that will translate into about 22.2 g of body fat being stored. Over a month, that will be approximately 666.7 g. Over a year, that will be 8 kg, or 17.6 lbs. Over 5 years, that will be 40 kg, or 88 lbs. This is only from carbohydrates; it does not consider other macronutrients.
There is no need to resort to the “tired pancreas” theory of late-onset insulin resistance to explain obesity in this context. Insulin resistance is, more often than not, a direct result of obesity. Type 2 diabetes is by far the most common type of diabetes; and most type 2 diabetics become obese or overweight before they become diabetic. There is clearly a genetic effect here as well, which seems to moderate the relationship between body fat gain and liver as well as pancreas dysfunction.
It is not that hard to become obese consuming refined carbohydrate-rich foods. It seems to be much harder to become obese consuming animal foods, or fruits.